Multimodality in storytelling and read-aloud sessions
During storytelling and read-aloud sessions in an additional language, storytellers and children orchestrate ensembles of semiotic resources to make meaning in interaction. Our research work draws on a multimodal perspective of interaction and communication.
Data are gathered during observations of storytelling and read-aloud sessions in Englishas an additional language (EAL) for children (such as the events of the initiative Let's Tell a Tale and TALES) and through the analysis of video recordings.
The overarching research questions addressed in this study is:
- What configurations of modes do storytellers and children use to co-construct meaning during read-aloud performances in EAL?
- What multimodal patterns of semiotic resources are used by storytellers and children to co-construct meaning during read-aloud performances in EAL?
Video-recordings of read-aloud perfromances in EAL are analysed to understand how storytellers and children make meaning during picturebook mediation. The purpose of our research is to identify configurations of semiotic resources through which storytellers and children interact and co-construct meaning. Results and research findings are limited to the context of the study and can potentially offer guidelines for teachers and educators to conduct effective read-aloud performances.
TMA (Tool for Multimodal Analysis)
TMA was developed as part of the research project in collaboration with a computer developer. TMA is a software that can be used to identify data structures and visualize correlations and patterns in the multimodal data. TMA serves as a tool that elaborates ELAN raw data and offers researchers functionalities and affordances to identify co-occurrences, patterns and structures in annotations within specific time spans.

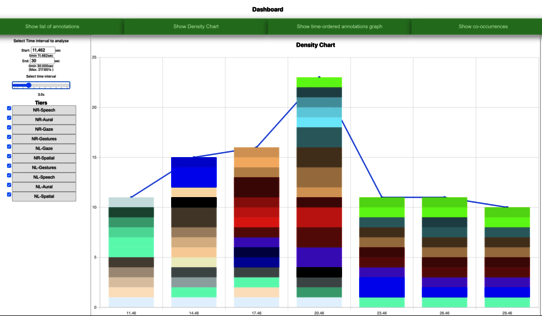

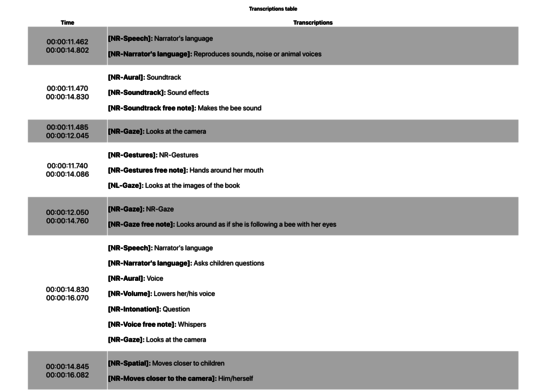
Related presentations:
Researching read-aloud sessions through TMA: a tool for multimodal data analysis
TMA was presented during the Bremen-Groningen Online Workshops on Multimodality in the session on Methods and Tools on 13 January 2023, 1.00-5.00pm.
Through examples of contextualized use of the software, the workshop offered an overview of TMA and presented some of its functionalities that allow to identify recurrent patterns of modes within specific time spans.
Multimodality in read-aloud sessions: picturebook mediation in English L2 with children
The software TMA was presented during the CETAPS / TEALS 5th Advanced Research Seminar On a verbal-visual continuum: Approaches to data collection and analysis (Universidade Nova de Lisboa - Portugal)
In this video-recording of Elisa Bertoldi's presentation Multimodality in read-aloud sessions: picturebook mediation in English L2 with children, the digital research tools ELAN and TMA are briefly introduced. Through ELAN and TMA the researcher can conduct an in-depth analysis of interaction (Norris, 2004) during read-aloud perfromances identifying patterns of semiotic resources used by storytellers and children to co-create meaning.
In this video, Elisa Bertoldi presents some key concepts and key terms for researching picturebook mediation during read-aloud perfrormances with children in English L2. The study is located within multimodality and unexplored perspectives are identified. Elisa presents the context of her research. The research site for data collection on picturebook mediation is the initiative TALES (Telling And Listening to Eco-sustainable Stories). In the video she describes the methodology for data gathering and the tools for video-annotations and data analysis. In the last part the last part of the video she presents some preliminary results.
Publications
Bortoluzzi Maria, Bertoldi Elisa and Marenzi Ivana. 2021. Storytelling with Children in Informal Contexts: Learning to Narrate across the Online/offline Boundary. In Sindoni, Maria Grazia and Moschini, Ilaria (eds.)Multimodal Literacies Across Digital Learning Contexts. Routledge Studies in Multimodality.London: Routledge, pp. 72-89.
Conferences
Teachers and teacher educators: Education and professional development for early language learning
CETAPS - Nova University Lisbon 12-14 November 2020
Conference website:
https://tedell2020.wordpress.com
Title of the presentation:
STORYTELLING WITH CHILDREN: THE PROJECT LET’S TELL A TALE
Abstract:
Research has widely demonstrated that storytelling is a powerful means to promote an early approach to a second/foreign language (Bertoldi and Bortoluzzi, 2019). The theoretical framework of reference of the present study includes the socio-semiotic perspective of interaction and communication. Storytelling sessions are analyzed as social practice considering the dynamic interaction of its components: the participants (narrators and children); the action (storytelling in English L2 as a multimodal practice) and the context in which storytelling events take place (Zhang, Djonov and Torr, 2015). Implications for pre-service and in-service teacher training include the reflection on multimodal resources, such as picture books (Mourão, 2015), and techniques and strategies for storytelling that can be adapted to different contexts and diverse audiences.
The presentation will discuss the results of involving student teachers as volunteer storytellers in the project Let’s Tell a Tale whichpromotes the use of storytelling in informal contexts in order to increase the exposure of very young learners and young learners to English as L2. It is the result of the collaboration between the University of Udine (Italy) and the municipal local libraries which host storytelling sessions in English L2 for children from 4 to 8 years oldconducted by student teachers of Primary Education.The presentation will discuss the data collected duringthe project through questionnaires, observation grids and analysis of video-recordings of interactions between children and student teachers during the storytelling sessions in the libraries.
The presentation will also show how the results of this study are used for student teacher and teacher training programs. Online communities, university workshops and open access online courses were organized to promote the use of narration as a fundamental means to help narrators promote children’s communicative skills in English L2.
Bibliographical references:
Bertoldi E. and Bortoluzzi M. 2019. Let’s Tell a Tale. Storytelling with Children in English L2. Udine: Forum Editrice.
Mourão, S. 2015. The Potential of Picture Books With Young Learners. In Bland, J. ed. Teaching English to Young Learners. Critical Issues in Language Teaching with 3-12 year olds.London: Bloomsbury Academic, pp. 199-218.
Zhang, K., Djonov, E. and Torr, J. 2016. Reading and Reinterpreting Picture Books on Children’s Television: Implications for Young Children’s Narrative Literacy. Children’s Literature in Education, 47 pp.129–147.
Video recording of the presentation:
Picturebooks and graphic narratives in education and translation: mediation and multimodality
CETAPS - Nova University Lisbon 24 – 26 June 2021
Title of the presentation:
MULTIMODAL ORCHESTRATION DURING STORYTELLING SESSIONS: THE ROLE OF PICTUREBOOKS
Abstract:
Children’s picturebooks are powerful tools for storytelling sessions in English L2 with children. Storytelling sessions based on picturebooks are authentic contexts for multimodal practice (Pinter, Martin and Unsworth, 2013). They offer children and adults potential for contextualized communicative interaction which is instantiated in a variety of modes. During storytelling sessions the multilayered convergence of modes allows the narrators and the audience to co-construct characters, settings and events presented in children’s picturebooks, through space organization, proxemics, voice quality, gestures and the use of props (Zhang, Djonov and Torr, 2016). Student teachers’ awareness of multimodal features in picturebooks allows them to orchestrate multimodal ensembles during storytelling sessions in English L2 in order to involve children and help them to co-create meaning.
The presentation will discuss the results of introducing picturebooks as multimodal resources for storytelling sessions in Primary Education courses and in the university projectLet’s Tell a Tale-Storytelling in English L2 with children. The theoretical framework of reference of the present study draws from the socio-semiotic perspective of interaction and communication (Bezemer & Kress, 2016). Implications for pre-service and in-service teacher training include the reflection on picturebooks as multimodal resources for storytelling in class and other educational settings. The presentation will discuss the analysis of data collected as student-teachers generated resources, questionnaires, observation grids and analysis of video-recordings of interactions between children and student teachers during the storytelling sessions.
Bibliographical references:
Bezemer, J. and Kress, G. 2016. Multimodality, Learning and Communication. A Social Semiotic Frame. Oxon: Routledge.
Painter, C. Martin, J. R. and Unsworth, L. 2013. Reading Visual Narratives. Image Analysis of Children’s Picture Books. Sheffield: Equinox.
Zhang, K., Djonov, E. and Torr, J. 2016. Reading and Reinterpreting Picture Books on Children’s Television: Implications for Young Children’s Narrative Literacy. Children’s Literature in Education. 47 pp.129–147.
Video recording of the presentation: